Современные методы позиционирования и сжатия звукаРефераты >> Программирование и компьютеры >> Современные методы позиционирования и сжатия звука
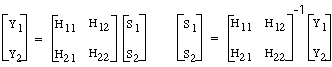
На практике, обратное преобразование матрицы не является тривиальной задачей.
· При очень низкой частоте звука, все функции HRTF одинаковы и поэтому матрица является вырожденной, т.е. матрицей с нулевым детерминантом (это единственная помеха для тривиального обращения любой квадратной матрицы). На западе такие матрицы называют сингулярными. (К счастью, в среде отражающей звук, т.е. где присутствует реверберация, низкочастотная информация не являются важной для определения местоположения источника звука).
· Точное решение стремиться к результату с очень длинными импульсными характеристиками. Эта проблема становится все более и более сложной, если в дальнейшем искомый источник звука располагается вне линии между двумя колонками, т.е. так называемый фантомный источник звука.
· Результат будет зависеть от того, где находится слушатель по отношению к колонкам. Правильное восприятие звучания достигается только в районе так называемого "sweet spot", предполагаемого месторасположения слушателя при обращении уравнения. Поэтому, то, как мы слышим звук, зависит не только от того, как была сделана запись, но и от того, из какого места между колонками мы слушаем звук.
При грамотном использовании алгоритмов CC получаются весьма хорошие результаты, обеспечивающие воспроизведение звука, источники которого расположены в вертикальной и горизонтальной плоскости. Фантомный источник звука может располагаться далеко вне пределов линейного сегмента между двумя колонками.
Давно известно, что для создания убедительного 3D звучания достаточно двух звуковых каналов. Главное это воссоздать давление звука на барабанные перепонки в левом и правом ушах таким же, как если бы слушатель находился в реальной звуковой среде.
Из-за того, что расчет HRTF функций сложная задача, во многих системах пространственного звука (spatial audio systems) разработчики полагаются на использование данных, полученных экспериментальным путем, например, данные получаются с помощью KEMAR. Тем не менее, основной причиной использования HRTF является желание воспроизвести эффект elevation (звук в вертикальной плоскости), наряду с азимутальными звуковыми эффектами. При этом восприятие звуковых сигналов, источники которых расположены в вертикальной плоскости, чрезвычайно чувствительно к особенностям каждого конкретного слушателя. В результате сложились четыре различных метода расчета HRTF:
· Использование компромиссных, стандартных HRTF функций. Такой метод обеспечивает посредственные результаты при воспроизведении эффектов elevation для некоторого процента слушателей, но это самый распространенный метод в недорогих системах. На сегодня, ни IEEE, ни ACM, ни AES не определили стандарт на HRTF, но похоже, что компании типа Microsoft и Intel создадут стандарт де-факто.
· Использование одной типа HRTF функций из набора стандартных функций. В этом случае необходимо определить HRTF для небольшого числа людей, которые представляют все различные типы слушателей, и предоставить пользователю простой способ выбрать именно тот набор HRTF функций, который наилучшим образом соответствует ему (имеются в виду рост, форма головы, расположение ушей и т.д.). Несмотря на то, что такой метод предложен, пока никаких стандартных наборов HRTF функций не существует.
· Использование индивидуализированных HRTF функций. В этом случае необходимо производить определение HRTF исходя из параметров конкретного слушателя, что само по себе сложная и требующая массы времени процедура. Тем не менее, эта процедура обеспечивает наилучшие результаты.
· Использование метода моделирования параметров определяющих HRTF, которые могут быть адаптированы к каждому конкретному слушателю. Именно этот метод сейчас применяется повсеместно в технологиях 3D звука.
На практике существуют некоторые проблемы, связанные с созданием базы HRTF функций при помощи манекена. Результат будет соответствовать ожиданиям, если манекен и слушатель имеют головы одинакового размера и формы, а также ушные раковины одинакового размера и формы. Только при этих условиях можно корректно воссоздать эффект звучания в вертикальной плоскости и гарантировать правильное определение местоположения источников звука в пространстве. Записи, сделанные с использованием HRTF называются binaural recordings, и они обеспечивают высококачественный 3D звук. Слушать такие записи надо в наушниках, причем желательно в специальных наушниках. Компакт диски с такими записями стоят существенно дороже стандартных музыкальных CD. Чтобы корректно воспроизводить такие записи через колонки необходимо дополнительно использовать технику CC. Но главный недостаток подобного метода - это отсутствие интерактивности. Без дополнительных механизмов, отслеживающих положение головы пользователя, обеспечить интерактивность при использовании HRTF нельзя. Бытует даже поговорка, что использовать HRTF для интерактивного 3D звука, это все равно, что использовать ложку вместо отвертки: инструмент не соответствует задаче.
Sweet Spot
На самом деле значения HRTF можно получить не только с помощью установленных в ушах манекена специальных внутриканальных микрофонов (inter-canal microphones). Используется еще и так называемая искусственная ушная раковина. В этом случае прослушивать записи нужно в специальных внутриканальных (inter-canal) наушниках, которые представляют собой маленькие шишечки, размещаемые в ушном канале, так как искусственная ушная раковина уже перевела всю информацию о позиционировании в волновую форму. Однако нам гораздо удобнее слушать звук в наушниках или через колонки. При этом стоит помнить о том, что при записи через inter-canal микрофоны вокруг них, над ними и под ними происходит искажение звука. Аналогично, при прослушивании звук искажается вокруг головы слушателя. Поэтому и появилось понятие sweet spot, т.е. области, при расположении внутри которой слушатель будет слышать все эффекты, которые он должен слышать. Соответственно, если голова слушателя расположена в таком же положении, как и голова манекена при записи (и на той же высоте), тогда будет получен лучший результат при прослушивании. Во всех остальных случаях будут возникать искажения звука, как между ушами, так и между колонками. Понятно, что необходимость выбора правильного положения при прослушивании, т.е. расположение слушателя в sweet spot, накладывает дополнительные ограничения и создает новые проблемы. Понятно, что чем больше область sweet spot, тем большую свободу действий имеет слушатель. Поэтому разработчики постоянно ищут способы увеличить область действия sweet spot.
Частотная характеристика
Действие HRTF зависит от частоты звука; только звуки со значениями частотных компонентов в пределах от 3 kHz до 10 kHz могут успешно интерпретироваться с помощью функций HRTF. Определение местоположения источников звуков с частотой ниже 1 kHz основывается на определении времени задержки прибытия разных по фазе сигналов до ушей, что дает возможность определить только общее расположение слева/справа источников звука и не помогает пространственному восприятию звучания. Восприятие звука с частотой выше 10 kHz почти полностью зависит от ушной раковины, поэтому далеко не каждый слушатель может различать звуки с такой частотой. Определить местоположение источников звука с частотой от 1 kHz до 3 kHz очень сложно. Число ошибок при определении местоположения источников звука возрастает при снижении разницы между соотношениями амплитуд (чем выше пиковое значение амплитуды звукового сигнала, тем труднее определить местоположение источника). Это означает, что нужно использовать частоту дискретизации (которая должна быть вдвое больше значения частоты звука) соответствующей как минимум 22050 Hz при 16 бит для реальной действенности HRTF. Дискретизация 8 бит не обеспечивает достаточной разницы амплитуд (всего 256 вместо 65536), а частота 11025 Hz не обеспечивает достаточной частотной характеристики (так как при этом максимальная частота звука соответствует 5512 Hz). Итак, чтобы применение HRTF было эффективным, необходимо использовать частоту 22050 Hz при 16 битной дискретизации.